선형회귀 알고리즘이란?
선형회귀 알고리즘은 1개 이상의 독립변수 x와 종속변수 y와의 상관관계를 모델링하는 방법
지도학습
labeled dataset을 바탕으로 x를 통해 y를 예측,설명
가설(hypothesis)
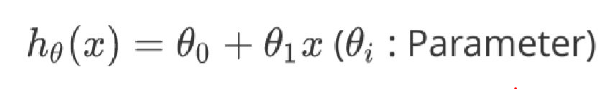
비용함수(cost function)

이 비용함수의 결과값이 작을수록 파라미터(가중치와 편향)은 좋은 파라미터일 것이다
즉, 비용함수를 최소화 하는 방향으로 학습을 시켜야한다.
이 비용함수가 최소값을 갖는 위치를 찾는 방식이 바로 경사하강법이다
경사하강법(Gradient descent)

선형회귀 코드 구현
라이브러리 선언
import numpy as np
from matplotlib import pyplot as plt
1. 데이터 생성
m = 100
x = np.random.randn(1,m)
y = 3 * x + np.random.rand(1,m) * 5
'''
x는 평균0, 표준편차1인 가우시안 분포를 따르는 임의의 난수를
(1,m) shape의 array
y는 x를 3배 하고 노이즈를 조금 주었음
'''x는 사실 100개의 데이터만 만들면 되는건데 왜 1차원의 벡터를 만들지 않고 굳이 2차원으로 만들었을까?
머신러닝에서 데이터는 나중에 concat을 할 수도 있고 다른 벡터들과의 연산의 편의성을 위해서
일반적으로 1차원으로 만드는 경우는 거의 없고 2차원으로 만든다고 한다.
2. 모델 정의
#모든 input data들에 대해 가중치 곱하고 편향 더하기 연산
def hypothesis(x, w, b):
pred = np.dot(x, w) + b
return pred
def cost(x, w, b, y):
loss = 1/2*(hypothesis(x, w, b) - y)**2 # loss = 1/2(h(x) - y)^2
cost = (1/m)*np.sum(loss, axis=1, keepdims=True) # cost = mean of batch losses
return cost
def derivative(x, w, b, y):
dw = ((1/m)*np.dot(x, (hypothesis(x, w, b) - y).T))[0][0] # d(cost)/dw = (h(x) - y)(h(x))' = (h(x) - y)*x
db = (1/m)*np.sum(hypothesis(x, w, b) - y) # d(cost)/db = (h(x) - y)(h(x))' = (h(x) -y)
return dw, db
def update(x, w, b, y, alpha):
w = w - alpha*(derivative(x, w, b, y)[0]) # w := w + alpha * dw
b = b - alpha*(derivative(x, w, b, y)[1]) # b := b + alpha * db
return w, b
3. 학습
w = 0
b = 0
def train(_iter, x, w, b, y):
for i in range(_iter):
w, b = update(x, w, b, y, alpha=0.01)
print ('cost =',cost(x, w, b, y)[0][0])
print ('w =',w)
print ('b =',b)
print ('\n')
return w, b
for i in range(10):
w, b = train(30, x, w, b, y)
plt.scatter(x,y)
line_x = np.linspace(-4,4,100)
plt.plot(line_x, line_x * w + b)
plt.show()여기서는 1 iteration과 1 epoch이 같다
4. 결과



학습이 진행될수록 파라미터들이 손실함수를 최소화하는 지점을 찾게된다
학습이 진행될수록 데이터들을 잘 표현할 수 있는 파라미터들을 찾게된다
머신러닝 관련 framework이 요구하는 데이터의 형식
예를들어 다음의 코드를 보면
from sklearn.linear_model import LinearRegression
reshaped_x = x.reshape((100,1))
reshaped_y = y.reshape((100,1))
model = LinearRegression()
model.fit(reshaped_x,reshaped_y)이 코드는 위의 작업을 scikit-learn으로 돌리는 코드이다
여기서 왜 reshape을 해주었을까?
앞으로 사용할 tensorflow같은 머신러닝 framework을 사용할 때 명심해야할 암묵적인 규칙이 있는데
바로 shape을 찍었을 때 가장 앞에 오는 숫자는 data의 개수를 의미한다는 규칙이다
예를들어 데이터의 shape이 (64,28,28,3) 는 (28,28,3)의 이미지 데이터가 64개 있다는 뜻이다
우리가 위에서 만든 x는 이러한 암묵적인 규칙을 지켜주지 못했으므로 scikit-learn의 모델에 넣어줄때
"가장 앞에는 데이터의 개수가 들어간다"는 규칙을 지켜주기 위해 reshape을 해준것이다!!
'딥러닝_이미지&영상처리' 카테고리의 다른 글
| 선형분류 알고리즘(Logistic Regression) (0) | 2019.11.09 |
|---|
